Ready for AI? Make Sure Your Data is, Too
Written by Gimmal Product Marketing
If your organization is exploring AI for records management, you’re not alone—and you’re not late. In a recent Gimmal education session, most attendees reported they were still exploring AI with no concrete plans yet. That’s normal. The smartest first step isn’t choosing an AI tool—it’s preparing your data so AI only learns from the right information.
Here’s a practical roadmap from the session, led by Jeff Tujetsch, on how Gimmal Discover helps you get AI-ready, without risking sensitive, proprietary, or misleading content.
Why Data Readiness Matters
AI is powerful, but indiscriminate. If you point it at everything, it can:
- Learn from sensitive data (contracts, HR files, legal communications, proprietary designs)
- Expose personally identifiable information (PII/PHI)
- Absorb outdated or redundant content that skews results
The goal: give AI only what you intend. That starts with four steps—identify, inventory, include/exclude, and enforce.

Step 1: Identify What You Have
Most organizations can’t fully describe what’s on their file shares, in SharePoint, OneDrive, or email. You don’t need perfect certainty—you need a systematic approach.
Think in high-level categories:
- Confidential: contracts, HR, invoices, legal communications
- Personal: employee or customer data (PII/PHI)
- Proprietary: formulas, designs, processes, trade secrets
Gimmal Discover helps you identify these with:
- Metadata analysis: file names, extensions, paths, dates, owners, sites, libraries, mailboxes
- Content search: keywords, phrases, Boolean expressions (AND/OR/NOT, proximity)
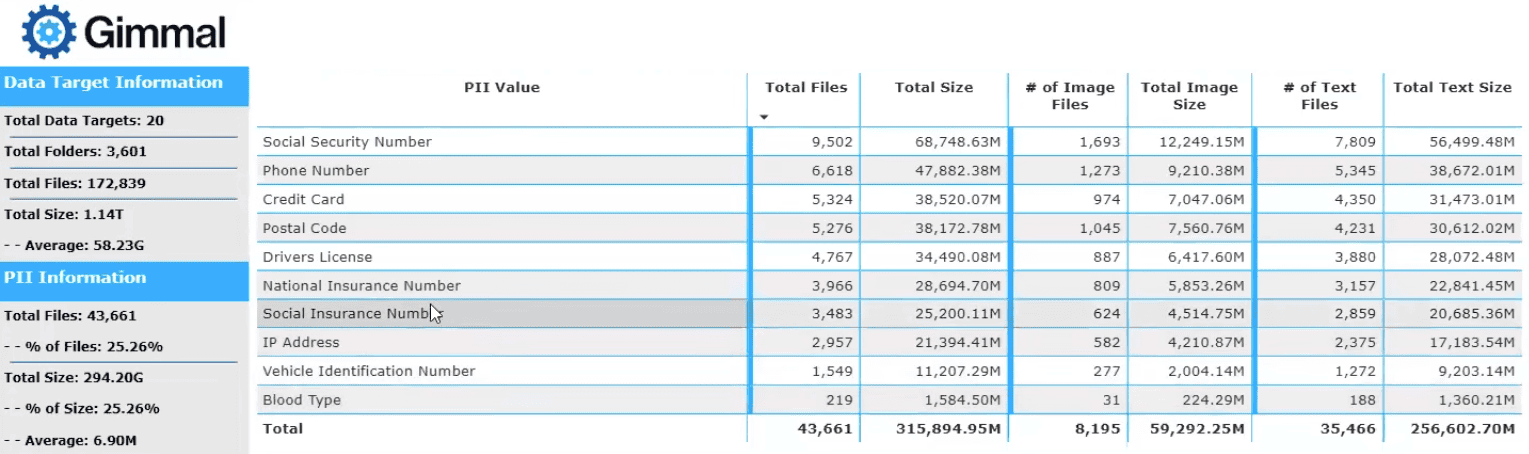
- Pattern detection (regex): Social Security numbers, national IDs, credit cards, driver’s licenses, health data, and more
Tip: Don’t draw hard lines on day one; expect to iterate as you learn.
Step 2: Inventory and Quantify
Once you can find the right content, quantify it:
- How much of each category exists?
- Where does it live (shares, sites, mailboxes)?
- Which file types are most prevalent?
- What percentage is likely safe for AI vs. needs exclusion?
Gimmal Discover integrates with Power BI to visualize:
- Labeled vs. unlabeled content by size and count
- Keyword/phrase match distributions
- PII/PHI findings by type and location
This gives stakeholders an evidence-based view of AI readiness.
Step 3: Decide on Inclusion vs. Exclusion
There are two viable stances:
- Inclusion-first: Build a clean, approved corpus for AI to learn from
- Exclusion-first: Block or remove sensitive or non-relevant content and allow everything else
Practically, most teams “cater to the exception”: exclude the smaller sensitive set rather than curating the entire estate—especially when dealing with hundreds of terabytes or more.
Step 4: Enforce with Repeatable Methods
Use multiple, reinforcing controls:
- Classification labels
- Automatically apply labels like Contract, Invoice, Privileged, Proprietary, PII, etc., based on metadata and content.
- Run simulations first to avoid false positives/negatives, then apply labels at scale.
- Labels persist with files (written to the file’s alternate data stream).
- Sensitivity labels
- Apply Microsoft Purview sensitivity and Copilot labels on Windows file shares.
- When files move to SharePoint/OneDrive, Copilot respects these labels for AI ingestion decisions.
- Isolation
- Move or copy approved content to a designated “AI ingest” location.
- Alternatively, sequester sensitive content away from AI-accessible repositories.
- Policy and automation
- Make rules per department, repository, or geography (to account for privacy laws and business variance).
- Combine metadata and content criteria, e.g., “Path contains /Legal/ AND extension in [docx, pdf] AND content contains ‘attorney-client’ → label Privileged.”
Don’t Skip ROT Remediation
Redundant, obsolete, or trivial data can pollute AI outcomes just as much as sensitive data can create risk. Clean it up early. Old or irrelevant content leads to misinformation and noise; remove or archive it before building your AI corpus.
Best Practices from the Field
- Start small, then scale: Pilot with a known subset where you can validate results.
- Simulate before labeling: Tune your rules to reduce errors.
- Use composite rules: Combine metadata + content for better precision.
- Keep labels manageable: You can create unlimited labels, but aim for fewer than 100 to avoid operational drag.
- Visualize for buy-in: Use dashboards to show progress and justify decisions.
Common Questions Answered
- Can we combine metadata and content? Yes—use AND conditions across path, extension, owners, and content matches.
- Can we tailor rules by department or region? Absolutely—Gimmal Discover supports fully customizable criteria per group or geography.
- Is there a max number of labels? No hard limit, but fewer, well-defined labels are easier to manage.
- Should we process ROT for AI readiness? Yes—remove outdated or trivial content to protect AI quality and reduce risk.
The Bottom Line
AI readiness isn’t about turning on a feature—it’s about curating your data with intention. Gimmal Discover helps you:
- Find and quantify what matters
- Label and protect what shouldn’t be learned
- Isolate what should be learned
- Carry those controls forward into Microsoft 365 and Copilot
Do that well, and when you’re ready to turn on AI, your data will be ready too.
View ROT Data Infographic

Ready to Take Control of Your Data?
If you’re facing challenges around AI readiness, data risk, compliance, or DSARs—Gimmal is here to help. Book a discovery session with us to see how we can empower your organization with actionable, efficient, and future-proof information governance.
Get Started or Learn More
Request a demo.
See us at upcoming events: AIM, ARMA, and more—check out our events page for more details.
Related Content

Podcasts
Podcasts Expert Interviews and Best Practices for Modern Information Governance 23 SEPT Navigating AI and Information Governance Part II – Insights from Gimmal & Office Labs Jason Coggins (Gimmal, UK & Europe) and Mike Nicholas (Office Labs) sit down for a...
Navigating AI and Information Governance – Insights from Gimmal & OfficeLabs
Navigating AI and Information Governance – Insights from Gimmal & OfficeLabs Jul 8, 2025 In a recent episode of the Gimmal Podcast, Jason Coggins (Gimmal, UK & Europe) and Graham Bidwell (OfficeLabs) sat down for a deep dive into the fast-evolving worlds of...
Stop Hoarding: Data Retention & Deletion Imperatives for Risk Mitigation
Stop Hoarding: Data Retention & Deletion Imperatives for Risk Mitigation Jun 11, 2025 At Gimmal, our mission is to help organizations effectively manage information, reduce risk, and ensure compliance in an ever-evolving regulatory landscape. In a recent webinar,...
End-to-End Email Records Management: How Gimmal & Colligo Are Automating Compliance for Modern Organizations
End-to-End Email Records Management: How Gimmal & Colligo Are Automating Compliance for Modern Organizations May 7, 2025 Managing records in a modern organization is no easy feat—especially when so much critical business information flows through email. That’s why...

Gimmal Extends Microsoft Purview Information Protection Solution for Enhanced Sensitive Data Labeling and Governance
Thursday, June 20, 2024 – HOUSTON, TX – Gimmal, the market’s only end-to-end information governance platform, announced today the launch of their Microsoft Purview Sensitivity Labels solution to extend and enhance sensitive data classification for unstructured...