
Any sufficiently advanced technology is indistinguishable from magic.
– Arthur C. Clarke
Gimmal Discover’s platform lets users automate policies for security, compliance, legal, human resources, IT and records management. To this end, our engineers have introduced machine learning (ML) to sift through data in order to locate and classify what’s present in a diversified data environment.
What is Machine Learning?
But … what exactly is machine learning? And how does it specifically apply to data governance?
The traditional definition of machine learning is credited to Arthur Samuel who in the 1950s devised a computer program to play checkers. Samuel defined machine learning as the field of study that gives computers the ability to learn without being explicitly programmed1. Samuel played thousands of games against himself and by studying which moves tended to lead to wins or losses, the program was able to learn which combinations of moves and strategies led to the desired outcome.
For a more formal, modern perspective, Tom Mitchell of Carnegie Mellon University describes machine learning this way:
A computer program is said to learn from experience with respect to some task and some performance measure2.
‘Learning’ is defined as the program’s performance on task — as measured by performance — improves with experience. In the checkers playing analogy, the experience would be the repetition of the program playing multitudes of games. The task would be playing checkers, and the performance measure represents the probability of winning the next game of checkers against some new opponent.
Many researchers feel the optimal method of machine learning is through algorithms known as neural networks. Neural networks attempt to mimic how the human brain learns. This may all seem rather academic but in reality, you probably experience machine learning on a daily basis without giving it much thought.
Whenever you visit Amazon, Netflix or a host of other commercial sites, you receive additional recommendations based on the initial search. There’s no way these sites can customize a personalized shopping experience for millions of users. Instead, algorithms land on recommendations, adapting to your past preferences or behavior.
Likewise, performing a web search is effective because Google or Bing have fine-tuned their machine-learning software to determine how best to rank the relevant pages. When you check your email and a filter has isolated relevant email from spam, that’s also machine learning. If TikTok makes a recommendation for you, or an iPhone or Android app utilizes facial recognition to identify you, that’s also machine learning. Self-driving vehicles are another example.
Gimmal Discover and Machine Learning
In Gimmal Discover, the workflows that are a core component of the Data Governance module have always included a “text contains” decision step. This decision allows the text of an item (file, message, database row, etc.) to be examined for specific keywords, phrases, patterns or regular expressions. This is useful in searching for social security numbers, credit cards or other predictable patterns. However, some types of information can be difficult to identify using a pattern, keyword or expression. Recognizing a name or street address, for example, is very difficult to do using a text-matching methodology.
To help meet this challenge, Gimmal Discover added its first machine learning component — a static natural language processing (NLP) model that is designed to identify name and/or address information within a content item. The ML test can be triggered within a Gimmal Discover workflow decision as shown here:
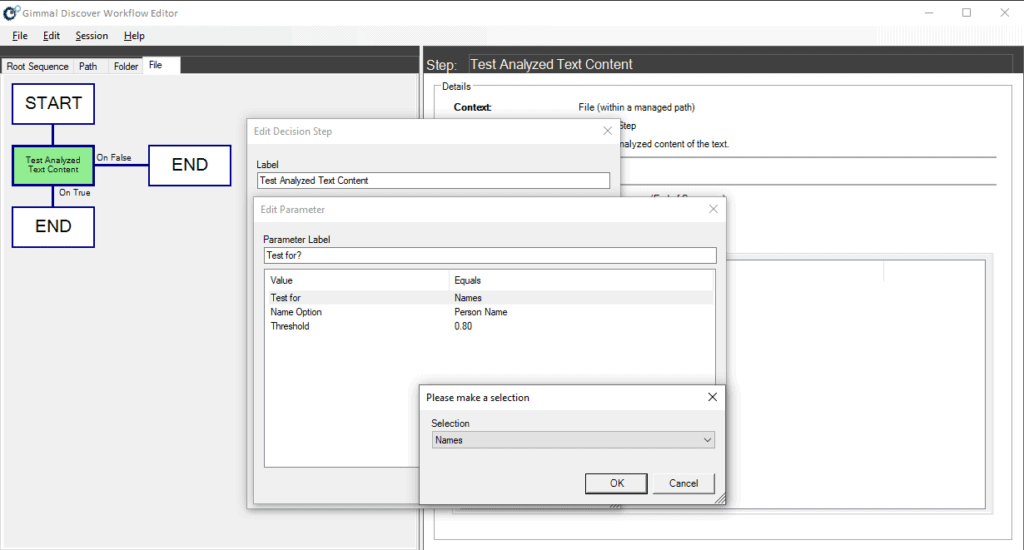
Notice the workflow decision includes a property for threshold percentage. The threshold indicates the degree of certainty that is returned from the ML model. In this case, only files that are determined to have an 80% or greater certainty of — including a name or address — will be processed through the ‘true’ side of the workflow decision.
Future Gimmal Discover versions are planned to introduce a robust ‘trained’ model. This will allow Gimmal Discover customers to build evaluation models based on their unique data.
To learn how machine learning can streamline your eDiscovery process, watch this on-demand webinar.
For more information about Gimmal Discover, or our other data governance, eDiscovery and document retention offerings, contact us today.
1Samuel, Arthur (1959). Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 3 (3): 210–229. CiteSeerX 10.1.1.368.2254. doi:10.1147/rd.33.0210
2Mitchell, T. (1997). Machine Learning. McGraw Hill. p. 2. ISBN 978-0-07-042807-2.